There are 2 types of databases.
· System databases
· User databases
1) System Databases
In SQL Server 2005 and above versions we have
1. Master database
2. Model database
3. MSDB database
4. Temp DB database
5. Resource database and
6. Distributed database
Master database:
1) The master database stores all the system-level information for SQL Server.
2) The data stored by the master database includes information for: configuration settings, logon accounts, linked servers and endpoints, user database file locations, and properties.
3) Due to the nature of the data stored, SQL Server cannot operate without the master database.
è If master database is corrupted then we have to rebuild the master database in sql server 2008 and above versions we can restore the database by installation media by using the following command.Run command prompt as administrator
Then type the following command
Cd Programfiles\Microsoft Sql Server\100\Setup.Bootstrap\Release press enter
Then type below command.
STEUP.EXE \QUIET \ACTION=REBUILDDATABASE \INSTANCENAME= “<NAME OF
INSTANCE>” \SQLSYSADMINACCOUNTS=”<MY WINDOWS ADMIN ACCOUNTS>” \SAPWD=<MY SA ACCOUNT PASSWORD> press enter.
Then master database is rebuilt.
Model database:
1) SQL Server uses the model database for creating new databases. When the “create database” statement is used, SQL Server copies the contents of the model database to the newly created database.
2) If there are any common database objects that would prove useful in all databases created by SQL Server, it is possible to add those objects to the model database. Then when a database is created by the SQL Server instance, the user defined objects will be copied to it along with the default objects.
If model database is corrupted then we have to rebuild master database first then we have restore model database from the last backup using the command .
Syntax:
restore database model from disk ='<path in which the backup file is located>' with replace
MSDB database:
1) The msdb database stores META DATA.
2) The msdb database is used by SQL Server to store information on operations performed by SQL Server. This includes information for: the SQL Server Agent, Database Mail, the Service Broker, log shipping, backup, and maintenance plan job parameters.
3) If msdb database is corrupted the rebuilding process is same as the model database.

NOTE: META DATA is the data about the data. ie., definition of the data .
Temp DB database:
1) As the name implies, SQL Server uses the tempdb database for storing temporary data and data objects. The tempdb database is used when an operation requires a temporary table, stored procedure, or other database object to be performed. Intermediary data for large sort operations is also stored in the tempdb database as well as temporary data for internal SQL Server operations.
2) Every time SQL Server is restarted, the tempdb system database is recreated thus clearing any temporary data stored during the last SQL Server session. In cases where a high volume of users and operations are performed with SQL Server the tempdb database can grow to use a significantly large amount of disk space.
If tempdb database is corrupted then no problem it will rebuild it self whenever the database gets restarted.
Resource database:
1) The resource system database was introduced with SQL Server 2005. This database is used for storing all the system views and stored procedures. Logically, each SQL Server database will contain all these system objects, however, they are physically stored within the resource database. The resource database is read-only and does not include any user data.
2) In previous versions of SQL Server, the system objects were stored in the master database. The motivation behind moving the objects to a separate database is to make updating the SQL Server more efficient. Improvements and fix-ups to the SQL Server system generally manifest mostly on the system objects. A separate database to store the system objects reduces the number of files that need to be replaced with an update.
Distributed database
1) The resource system database was introduced with SQL Server 2005. This database is used for storing all the system views and stored procedures. Logically, each SQL Server database will contain all these system objects, however, they are physically stored within the resource database. The resource database is read-only and does not include any user data.
2) In previous versions of SQL Server, the system objects were stored in the master database. The motivation behind moving the objects to a separate database is to make updating the SQL Server more efficient. Improvements and fix-ups to the SQL Server system generally manifest mostly on the system objects. A separate database to store the system objects reduces the number of files that need to be replaced with an update.

Note:
ð Resource database are new features of sql 2005 and above version.
The databases created by the user are called as user databases
Database creation:
There are two ways of database creation they are
1) By writing T-sql command as
USE MASTER
GO
CREATE DATABASE <database name >
ON PRIMARY (NAME=’<logical name>’, FILENAME=’<path in which the data file is to be stored>’, SIZE=initial size of database>, MAXSIZE=<maximum size of database>, FILEGROWTH=<size of growth in MB >)
LOG ON (NAME=’<logical name>’, FILENAME=’<path in which the data file is to be stored>’, SIZE=<initial size of database>, MAXSIZE=<maximum size of database>, FILEGROWTH=<size of growth in % of initial size >)
For example :
create database test
on primary
(
name='test',
filename='E:\test.mdf',
size=2mb,
maxsize=50mb,
filegrowth=2mb
)
log on
(
name='test_log',
filename='E:\test_log',
size=2mb,
maxsize=50mb,
filegrowth=15%
)
go
2) BY GUI METHOD:
ð Right click on the database, then click on new database.

ð In that give the name of the database you want to create .

ð If you want to change the initial size , max size & file growth change it by clicking on it as shown in below .

We can change collation for the particular database , recovery model and even compatibility level
By editing options.

Click on Ok we can create new database.
NOTE :
· It best practice to keep the data file and log file in separate drives.
· If we specify the max size then it will be taken as restricted growth else it will keep on growing and occupy the entire drive so it’s best practice to keep the filegrowth to restricted .
· As a best practice file growth of the data file should be in MB and log file in % of size.
· If we do not specify the file initial size it allocate 2MB for the new database.
TO DELETE DATABASE :
By T-sql cmd:
DROP DATABASE [name of the database to be removed]
For example:
USE [master]
GO
DROP DATABASE [test11]
GO
BY GUI METHOD:
ð Right on the database you want to delete and choose DELETE as shown below.


TO GET THE INFORMATION ABOUT PARTICULAR DATABASE THE CMD IS :
USE <databse name>
GO
SELECT * FROM sys.sysfiles
For example :
use test
go
select * from sys.sysfiles

To get the information about all the databases present in the server then the cmd is
SELECT * FROM sys.sysaltfiles

We can get the informatin about
1) File id =1 for mdf & 2 for log file ,it will keep on increse by adding ndf files
2) Groupid= 1 for data file & 0 for log file
3) Size =size of file
4) Growth= rate of file growth
5) Database id = it keep on incresing by addition of databases
6) Name= name of file
7) Filename(path) = path in which they are physicaly stored
To get the information about server cmd is
USE MASTER
GO
SELECT SERVERPROPERTY('edtion') as edtion,
SERVERPROPERTY('productversion') as version,
SERVERPROPERTY('productlevel') as servicepack,
SERVERPROPERTY('servername')as servername
We can get the information as shown below

To add new file
Syntax:
ALTER DATABASE <name of the database > ADD FILE ( NAME=’<name of the file you want to add >’, FILENAME=’<path to store the file >, SIZE=<initial size>, MAXSIZE=<max size of the file >, FILEGROWTH=<rate of filegrowth>) TO FILEGROUP <name of filegroup to which file is to be added>
For example:
USE [master]
GO
ALTER DATABASE [test] ADD FILE
( NAME = N'test', FILENAME = N'F:\DATA\test.ndf' ,
SIZE = 3072KB , FILEGROWTH = 1024KB ) TO FILEGROUP [test_fg1]
GO
TO DELETE FILE:
Syntax:
ALTER DATABASE <database name >REMOVE FILE <logical file name to be removed>
Example
ALTER DATABASE test REMOVE FILE TEST2
1) BY GUI METHOD :
ð Right click on database in which you want to add the file and choose properties.
ð Then right on file and choose ADD to add new file as shown we can choose file group , size of file , max size and file growth


We can also choose the file path as shown (default it as the master database path )

TO ADD NEW FILE GROUP:
1) By T-sql cmd
USE <name of the database >
GO
ALTER DATABASE <database name> ADD FILEGROUP <name of file group>
GO
For example :
USE test
go
ALTER DATABASE test ADD filegroup test_fg1
go
2) BY GUI METHOD:
Right click on the database in which you want to create the file group and choose the properties

We can add a new file group by clicking on the Add button as I have added newfilegroup now
Even we can remove it by selecting particular filegroup and clicking on remove .
T-sql cmd for that is
USE <name of database in which filegroup is present>
Go
ALTER DATABASE <database name > REMOVE FILEGROUP < file group name>
For example :
USE [test]
GO
ALTER DATABASE [test] REMOVE FILEGROUP [test_fg1]
GO

Now adding file to file group
ALTER DATABASE TEST ADD FILE ( NAME=’<file name>,FILENAME=’<path to be stored>,SIZE=<initial size>,MAXSIZE=<maximum file size>,FILEGROWTH=<rate of file growth >) TO FILEGROUP <name of the file group >
Some of the operations on databases
1) To change the logical name file in a database
ALTER DATABASE <database name>, MODIFY FILE ( NAME=’<old logical name>, NEWNAME=’<new logical name >’)
For example :
ALTER DATABASE test MODIFY FILE ( NAME='testold',newname='testnew')
2) To change the file path
ALTER DATABASE <database name>, MODIFY FILE ( NAME=’< logical name>, FILENAME=’<new file location >’)
For example:
ALTER DATABASE test MODIFY FILE(NAME='test', filename='E:\sqlserver\data\test.ndf')
 NOTE:
NOTE:
Once the file path is changed it is noted in system catalog /master catalog ,the master treates the file has been boved to new location ,but actual file in previous path only .
After restart of sql server/database the path of the file has to be moved to new location manually .
Else the master can not recoganise the file and it can not be accesed .
To change the size of the file :
ALTER DATABASE < database name> MODIFY FILE ( NAME=’<logical name of file>’, SIZE=<new file size >)
For example:
ALTER DATABASE test MODIFY FILE ( NAME='test12',size=50mb)

NOTE: we have to specify the more then the default file size.
If we do not specify KB or MB it will take as KB by default.
PROPERTIES OF DATABASE
There are 9 properties of databases we can find them by right clicking on the database and choose properties
They are
1) General
2) File
3) File group
4) Options
5) Change tracking
6) Permissions
7) Mirroring
8) Transactional log shipping
1)General : (we can just view the information here)
we can see the properties such as
1) Backup: it will give the information about the last backup of database and log backup timings
2) Database : it provide the information about
ð Name = name of the database
ð Status = status of database either online or off line
ð Owner= who created the database
ð Date created= date of creation of the database
ð Space available= free space available in the database
ð Number of users= total number of users connected to database
3) Maintenance : it will provide the information of the collation of the database

2)File: 0
We can have the following information about files in database
Database name: shows the name of the database
Database owner: who created the database.
Database file information: as
Logical name, file type, file group, autogrowth , path, file name.

File group :
In file group we can find the information about name of file group and number of files present in a file group
As shown we can add file groups and even delete them by using ADD and REMOVE option.

Options:
In options we can have information about
1) Collation= we can change the language of the particular database as shown

2) Recovery model = type of recovery model as full or bulk_logged or simple as
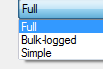
3) Compatibility level = version of the compatibility as shown

80 ,90 ,100 are version codes
and some other options such as

==>Auto Close
Specify whether the database shuts down cleanly and frees resources after the last user exits. Possible values are True and False. When True, the database is shut down cleanly and its resources are freed after the last user logs off.
==>Auto Create Statistics
Specify whether the database automatically creates missing optimization statistics. Possible values are True and False. When True, any missing statistics needed by a query for optimization are automatically built during optimization.
==>Auto Shrink
Specify whether the database files are available for periodic shrinking. Possible values are True and False.
==>Auto Update Statistics
Specify whether the database automatically updates out-of-date optimization statistics. Possible values are True and False. When True, any out-of-date statistics needed by a query for optimization are automatically built during optimization.
==>Auto Update Statistics Asynchronously
When True, queries that initiate an automatic update of out-of-date statistics will not wait for the statistics to be updated before compiling. Subsequent queries will use the updated statistics when they are available.
When False, queries that initiate an automatic update of out-of-date statistics, wait until the updated statistics can be used in the query optimization plan.
Setting this option to True has no effect unless Auto Update Statistics is also set to True.
The AUTO_UPDATE_STATISTICS_ASYNC option affects how automatic statistics updates are applied to your SQL Server database. This option is set database by database and the default setting for this option is disabled.
When this option is enabled, the Query Optimizer will not wait for the update of statistics, but will run the query first and update the outdated statistics afterwards. Your query will execute with the current statistics and a background process will start to update the statistics in a separate thread. It should be noted that the Query Optimizer may choose a suboptimal query plan if statistics are outdated when the query compiles. When this background operation is complete, the new query requests will use the new updated statistics.
When this option is disabled, the Query Optimizer will update the outdated statistics before compiling the query therefore possibly getting a better plan based on the most current statistics. This is referred to as synchronous statistics updates.
When to Use Asynchronous Statistics?
This option enables faster plan generation, but may create sub-optimal query plans because the plan compilation may be based on stale statistics.
Asynchronous statistics can be beneficial if the statistics update requires a significant amount of time and your queries cannot wait for it to complete.
You can get more predictable query response times with asynchronous statistics updates if your SQL Server frequently executes the same query or similar cached query plans.
The Query Optimizer can execute your queries without waiting for updated statistics when the AUTO_UPDATE_STATISTICS_ASYNC option is used. This way none of your queries will be delayed when the statistics are updated. It is also possible that some applications experience timeouts when the statistics are updated before running the query. This situation can be avoided by enabling asynchronous statistics updates.
When Not to Use Asynchronous Statistics?
It is recommended to disable the AUTO_UPDATE_STATISTICS_ASYNC option when your SQL Server executes operations that significantly change the distribution of your data, like truncating a table or running bulk updates on a large percentage of the rows.
Using synchronous statistics will ensure statistics are up-to-date before executing queries on the changed data. It is recommended to use this when your queries can wait until the statistics are updated. In most cases this is very minimal and you will not notice this, that is why this is the default behavior.
The actual screen is

In recovery there are 2 options they are
1) CHUCKSOME
2) TORN_PAGE_DETECTION as shown

CHECKSUM: it will just verify the page when database, while staring up it will not show the errors (it is preferable because of performance impacting on the database startup)
TORN_PAGE_DETECTION: this will show the corrupted pages as errors while starting of database.
Dear Sir, I am extremely thankful for your website as it helps to recall from very basic to extreme depth of sql.I have one request by mistake in the system database section the resource and distribution db have defined in same way ,can you recheck it again
ReplyDelete